Personally I always like to read how other companies do software development, but sharing our way is probably just as interesting to others. In this post I will describe what a typical Hippo CMS development cycle looks like, how the product is build and how we do continuous integration at Hippo.
For those of you new to the Continuous Integration concept here is short list of the core values:
- Maintain a code repository
- Automate the build
- Make the build self-testing
- Everyone commits to the baseline every day
- Every commit (to the baseline) should be built
- Keep the build fast
- Test in a clone of the production environment
- Everyone can see the result of the latest build
- Automate deployment
Along the way you will see how we handle each of these points, but let’s start at the beginning with the development environment of a typical software developer working at Hippo.
The development environment
At Hippo, we as developers can choose our own preferred development platform. Being Windows, any Linux distribution or Mac. Hippo CMS is a Java based web application. Our standard developer environment therefore contains Java 7, Apache Maven (for build and dependency management) and as an IDE the majority of developers at Hippo prefer IntelliJ Ultimate with Eclipse coming in second.
As a version control system for most of our code we use our public Subversion repository. I say most, because a few months back we adopted AngularJS into our stack, which required back then to have some parts in Git / Github. I will explain more about why later in this post.
Development strategy wise we do a lot of trunk based development. For features that will take more than a couple of days we tend to use feature branches, which we keep in sync with the trunk as often as possible to prevent getting into a merge hell. Since software is never without bugs, we fix bugs in the product first on trunk before they get back-ported to one of the maintenance release branches.
Integrating the changes
I think our CI setup is quite common for a Java based project. We use Hudson as our continuous integration server (we have plans to migrate to Jenkins). Our Hudson contains different jobs for different parts of our CMS stack ( CMS, HST, Repository and additional modules like replication, relevance, etc). Hudson polls the Subversion repository for changes and when a change is detected the Maven build is started and all code gets compiled, unit tested (JUnit) and a bunch of integration tests are run. Commits happen as often as possible, so this cycle happens at least multiple times a day.
As I mentioned before we adopted AngularJS for our CMS UI. Front-end development has changed a lot over the last 5 years. With a framework like AngularJS this also required us to rethink our current build environment, because for AngularJS based projects it’s quite common to use a combination of npm (package management), Bower (dependency management) and Grunt (task automation). Now front-end developers are used to working with these tools these days, but coming from a more Java back-end oriented background we wanted to have our front-end and back-end developers to be happy and use their own preferred set of tools. Maven itself is just focused on Java based dependencies, so we needed to figure out how to get this ‘new stuff’ to play nicely with our current build lifecycle. There are several ways of doing this actually and some quite nice examples can be found in the using Grunt and Maven together post by @addyosmani.
When we started with Bower, it was only possible to have dependencies stored in a git repository, hence we have some of our code on Github. These days that’s not needed any more and you can store your dependencies in different systems, like subversion, git and also on a local filesystem (like we do).
One thing that is specific to how we combine these technologies is probably how we package and distribute these dependencies. Our Javascript dependencies are packaged as .zip based artifacts with the maven-assembly-pluginand deployed to our nexus repository just like we do with our normal Maven based artifacts. They have a separate release cycle and are distributed separately from their CMS UI component. The hippo-plugins project is an example of this project setup.
Now when our CI server (or a developer) builds such a CMS component these .zip based artifacts are fetched in the initialize phase of the Maven build lifecycle. The build downloads and copies the dependencies from our remote maven repository into our build target directory. These downloaded zip files are then used by Bower as local dependencies. Once that’s done the default Maven build cycle continues and npm, bower and grunt are run during the generate-sources phase, so this has happened before we actually create a package out of the Java based CMS component. See the following XML snippet of our maven pom.xml:
<build>
<defaultGoal>package</defaultGoal>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>${maven.plugin.dependency.version}</version>
<executions>
<execution>
<id>fetch-bower-dependencies</id>
<phase>initialize</phase>
<goals><goal>copy-dependencies</goal></goals>
<configuration>
<includeGroupIds>org.onehippo.cms7.frontend</includeGroupIds>
<includeArtifactIds>
hippo-plugins,
hippo-theme
</includeArtifactIds>
<stripClassifier>true</stripClassifier>
<stripVersion>true</stripVersion>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>${maven.plugin.exec.version}</version>
<executions>
<execution>
<id>npm-install</id>
<phase>generate-sources</phase>
<goals><goal>exec</goal></goals>
<configuration>
<executable>npm</executable>
<commandlineArgs>install</commandlineArgs>
</configuration>
</execution>
<execution>
<id>bower-install</id>
<phase>generate-sources</phase>
<goals><goal>exec</goal></goals>
<configuration>
<executable>bower</executable>
<commandlineArgs>install</commandlineArgs>
</configuration>
</execution>
<execution>
<id>grunt-build</id>
<phase>generate-sources</phase>
<goals><goal>exec</goal></goals>
<configuration>
<executable>grunt</executable>
<commandlineArgs>build</commandlineArgs>
</configuration>
</execution>
<execution>
<id>grunt-test</id>
<phase>test</phase>
<goals><goal>exec</goal></goals>
<configuration>
<executable>grunt</executable>
<commandlineArgs>test</commandlineArgs>
<skip>${skipTests}</skip>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
When Bower is executed it will just find the dependencies in the local target directory and picks them up. See this little snippet from our bower.json file.
{
"name": "hippo-addon-channel-manager-frontend",
"dependencies": {
...
"hippo-theme": "./target/dependency/hippo-theme.zip",
"hippo-plugins": "./target/dependency/hippo-plugins.zip",
}
}
This sort of sums the complexity of our build and how it’s handled by our CI server. Untill this stage we’ve talked about integrating changes, but now a last step in this whole cycle would be to automate the deployment.
‘Nightly’ deploys
Now when all builds are successful we have one final step in the process which is creating a distribution of our demo website project (also known as GoGreen) based on the latest version of the entire stack. We chose to use a real project, because it helps us keep track of what kind of effect a change has on an existing project running an older version of the stack. The distribution will be stored in our nexus repository from which it will be fetched by a cron job on the internal test server. Once the distribution is on the test server it will be unpacked and deployed in an existing Tomcat container. This makes all the new features available to the QA team and product owners, so they can see the ‘current’ state of the product.
So the overall CI process ends up looking quite simple and is shown in the following diagram.
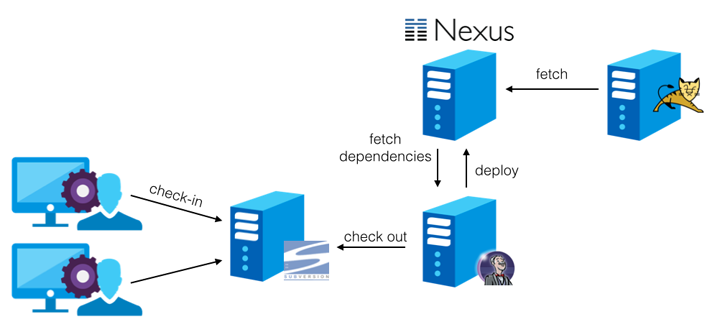
We don’t actively push a new distribution to the test server yet so there is still room for improvement, but this is our current setup and it’s serving us really well.