In 2022, when I was accepted into the AWS Community Builders program, I was amazed by the abundance of high-quality content generated by the broader AWS community. While most community builders publish their blog content on personal websites, Medium, or Hashnode, it is common for this content to be (re)published on the dev.to platform within the AWS Community Builders organization. It currently acts as a hub for blog content created by AWS community builders.
I didn’t frequently visit the dev.to platform and also was not really using an RSS reader anymore, so I began exploring alternative solutions. Most of the interesting articles I usually find on Twitter/X. I sought to find an existing Twitter account sharing the community builders content but was unsuccessful. Being a builder myself, I decided to create a fresh Twitter account (@aws_cb_blogs) and wanted to create a fully Serverless architecture. In this post I’ll explain how the architecture has evolved over time and what are some of the things to come.
The initial idea
As a first iteration I decided to put something together rather quickly. I needed three component:
- a component to read and parse the rss feed.
- a component to turn posts into tweets.
- a schedule to make sure new items are being picked up.
To initiate the entire process I needed to have a solution similar to a cron job (scheduled job). AWS offers this in the form of Amazon EventBridge Scheduler. It’s a pretty straightforward service which allows you to easily create a scheduled call to more than 270 AWS services and over 6,000 API operations.
I decided to split the business logic of the application by responsibilities into different lambda functions and I ended up with the following architecture.
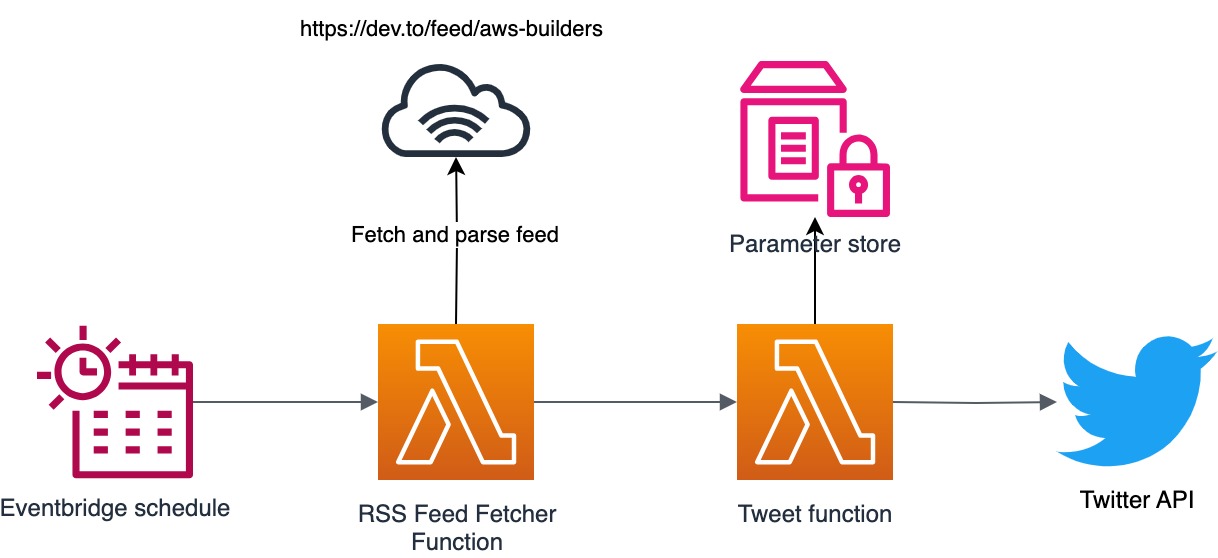
The Twitter API requires authentication with keys and I needed to store them in a secure place. It’s better to not store them with(in) the Lambda, so I decided to put them into Systems Manager Parameter Store. For each cold start invocation of the Tweet function a call is made to parameter store to fetch the API credentials.
While building, I quickly realized I needed some persistent storage as the RSS feed could contain the same items during a consecutive fetch. I did not want the bot to repeat an already tweeted post so I needed some sort of storage for storing the tweetid for a specific post. I needed a simple persistent database and decided to use DynamoDB as the database for keeping track of the posts. The great thing about DynamoDB is that it’s a fully managed serverless databases and it offers a pay as you go model. It’s really cheap for most cases and I only pay $0.01 a month for using it for this application.
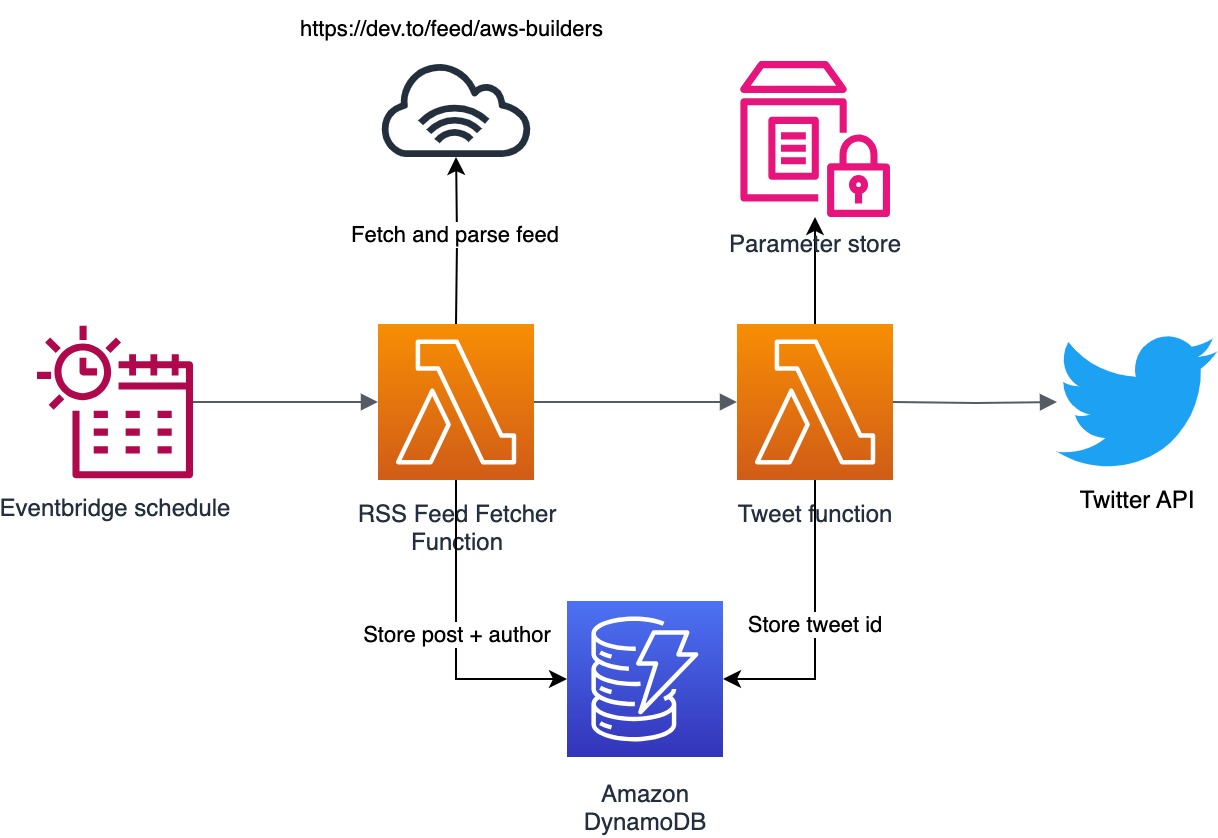
Improving the design
A few weeks later I decided that I wanted to improve the architecture a bit and decided to decouple the two Lambda components by means of an SQS queue. The advantage of using the SQS queue is that when the function fails the item(s) being processed is not removed from the queue and will be retried at a later moment in time. For consecutive failures I added a dead letter queue (DLQ), so in case the messages on the queue can’t be processed, they will be moved to the DLQ. If there is an error in the component or at the Twitter API I will be able to inspect the messages and re-drive them. You might think this is not necessary, but once Twitter announced their new API plans in March 2023 , the function that was responsible for tweeting was unable to send out tweets until I subscribed to the new usage plan. Because of the DLQ, it was a matter of re-driving the messages instead of trying to get the changes to propagate again.
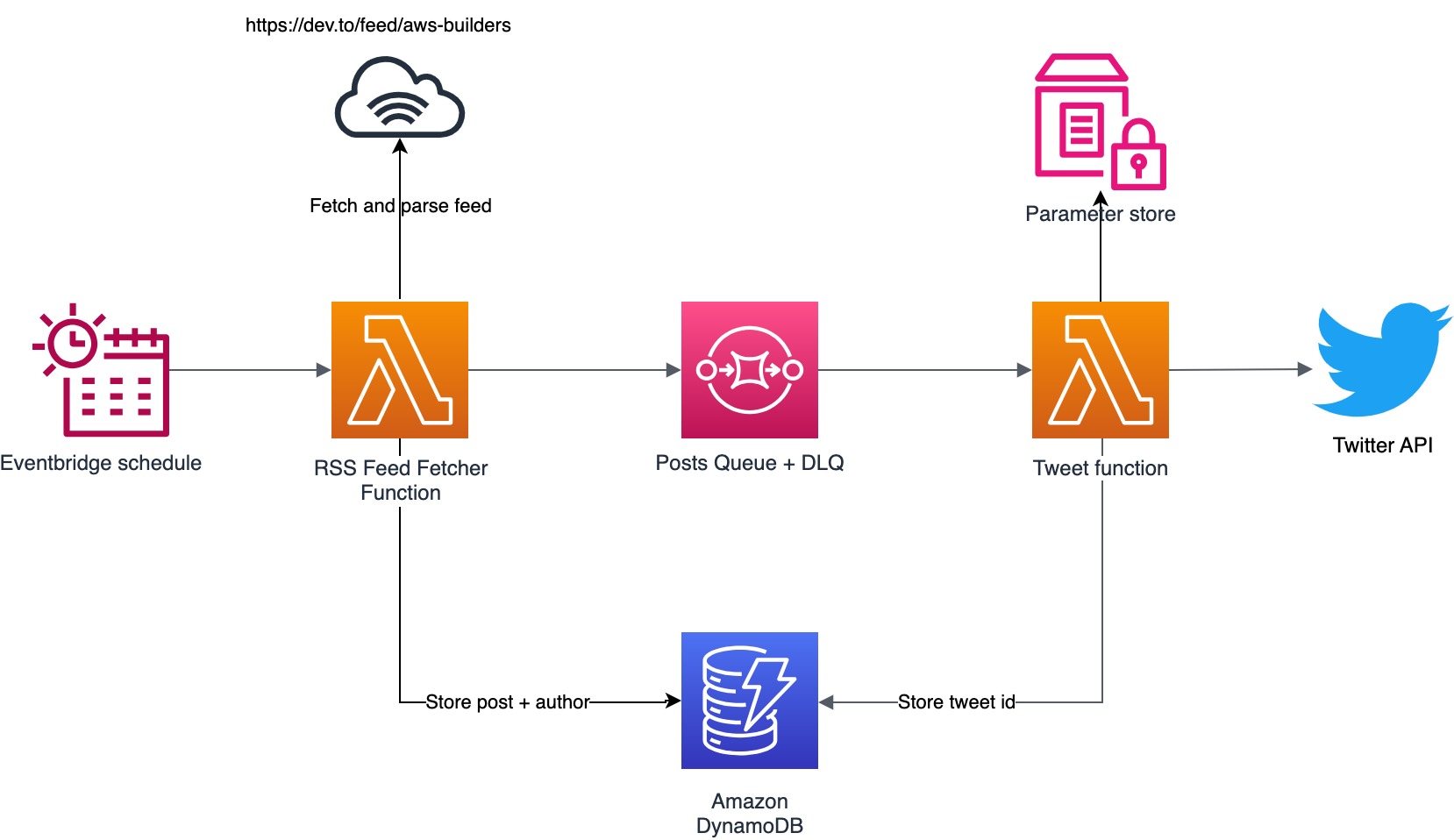
New feature imposed more changes
Some authors on the dev.to platform have added their Twitter handle to their profile. I thought it would be great to be able to mention the author in the tweet when it’s send out. It gives the tweet a bit more body and the author is notified when the post hits the twitter platform.
New post by @cloudsege
— AWS Community Builders Blogs (@aws_cb_blogs) November 7, 2023
AWS IAM User Management: How to get User Information using Lambda and Amazon S3https://t.co/Txs7zMzbyW#aws #cloud #python #serverless
From the RSS feed I only get the dev.to username of the author. The twitter handle is only available on the post itself, so I decided to add a third component to get the Twitter handle for the author.
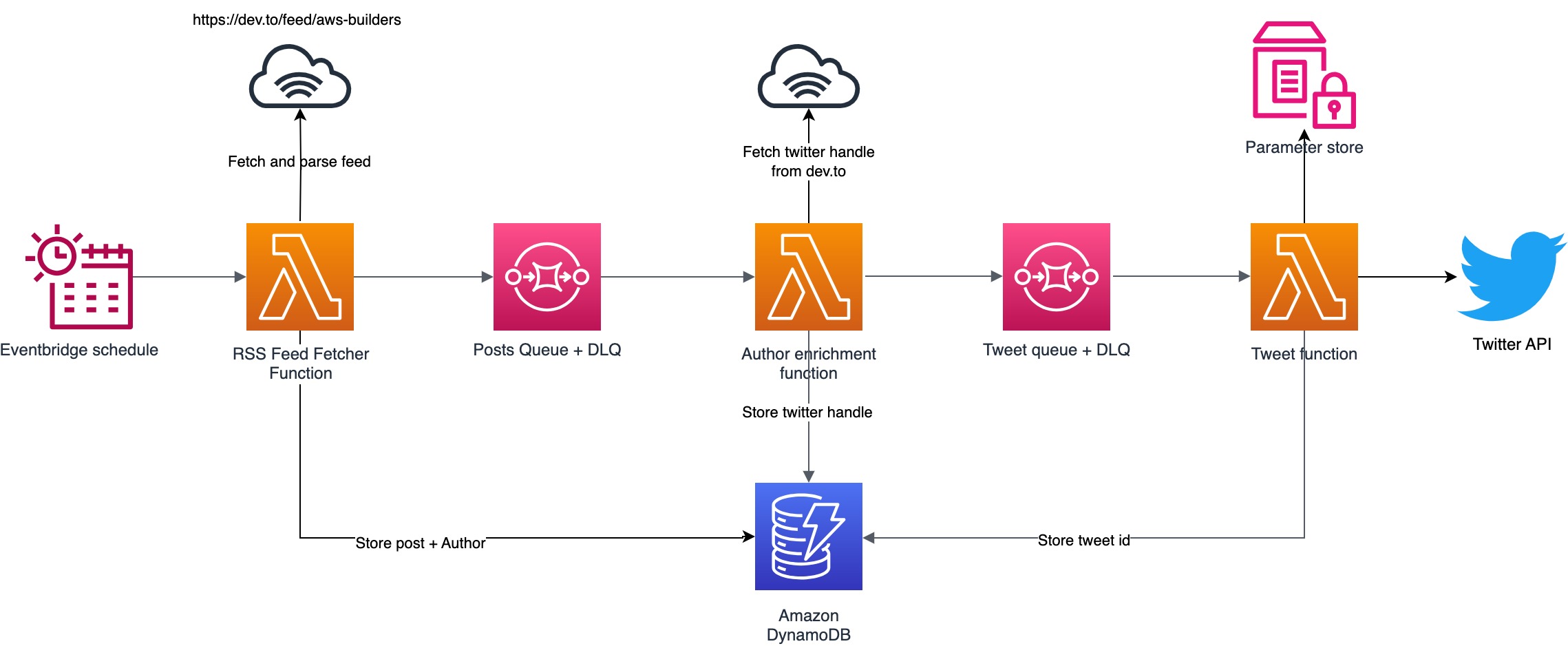
What’s next?
This architecture has been running fine for quite some time now and I’ve even deployed the same stack for a bot for the posts by the AWS Heroes, but I still have some improvements in mind:
- Replacing the SQS queue for the posts by DynamoDB Streams. The author enrichment function would only have react to events in the stream. That would remove a bit of complexity and responsibility from the feed parser function.
- If I look at the flow it looks a bit like a workflow. I’m considering to replace the entire thing and with a step functions workflow.
- Integrate with Amazon Bedrock for generating summaries of the posts the bot is posting to Twitter. It would improve the Twitter posts a bit instead of just mentioning the author and the title of the post.
- Extend the bot to also publish to other platforms. I’ve been looking into Threads, but it does not seem to have a public API yet. Not sure how big the AWS community is on other social platforms. Feel free to reach out if you prefer to follow all the great content on your social media platform of choice.
In a follow up post I will dive into the technical details of how the functions work and will take a look at some of the best practices for building Lambda functions. If you have some comments/ideas/feedback, feel free to reach out!